Как настроить сбор данных без лишней нагрузки на инфраструктуру? Рассказала команда GMonit

13 марта мы провели технический вебинар «Сэмплирование в GMonit: как выбрать нужные данные и не потерять важное», в ходе которого обсудили, как настроить инструмент для сбора критически важных метрик, и рассказали, какие функциональные возможности GMonit помогают снизить затраты на мониторинг.
Технический директор GMonit Антон Новоженин объяснил, что такое распределенный трейс, как устроены спаны и почему сбор 100% данных — не всегда хорошая идея.

CTO дал определение сэмплированию и разобрал его основные типы — head-based и tail-based. Зрители трансляции получили рекомендации по выбору подходящего метода в зависимости от задач и особенностей архитектуры. Например, поговорили о пробабилистическом, Rate-limited и Rule-based сэмплировании, сэмплировании на основе ошибок, латентности, аномалий и др.
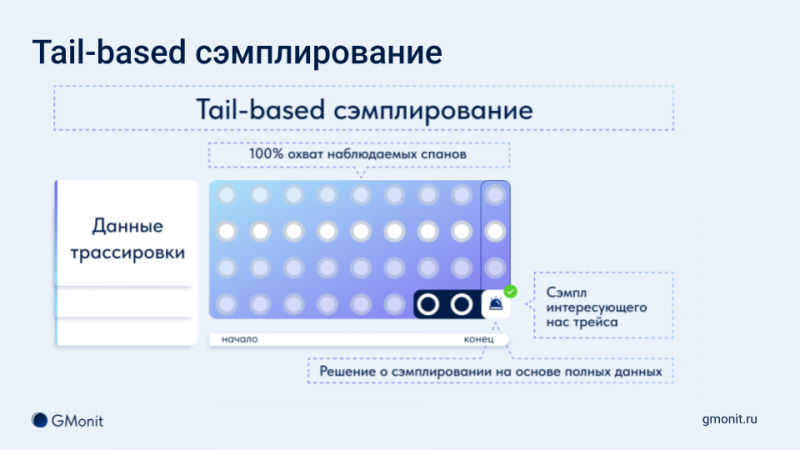

Участники рассмотрели три ситуации, когда оптимизация объема данных может навредить:
- Необходимость полной детализации или жесткие нормативные требования.
- Малый объем трафика.
- Этап разработки или тестирования.
Также спикер рассказал, какие протоколы телеметрии поддерживает GMonit и пояснил, как сэмплирование реализовано в observability платформе.
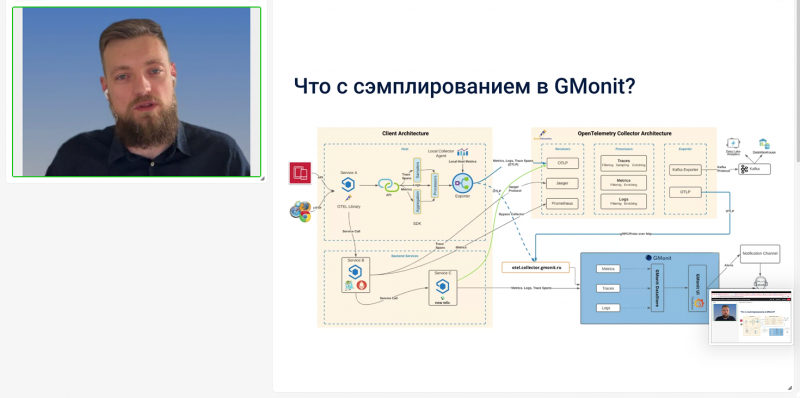
В финальной части вебинара состоялась QA-сессия, где участники получили ответы на свои вопросы:
- Какой тип семплирования наиболее близок принципу 20/80.
- Как использовать GMonit, если внутри приложения работают агенты New Relic.
- Насколько увеличиваются затраты на вычислительные мощности при выборе tail-based сэмплирования?
- Как собрать все спаны с ошибками, не используя tail-based сэмплирование, и др.
Бонусом — спикер предложил участникам попробовать Lite-версию GMonit на облачной платформе Yandex. Этот инструмент хранит данные в течение трех дней и предоставляет весь необходимый функционал для анализа ключевых показателей производительности и решения базовых задач APM-мониторинга.
Предлагаем к просмотру видеозапись выступления:
Эта тема в видео

Cмотреть видео







