
Анкета
Ответы на вопросы анкеты помогут точнее сформировать ваш запрос
Нажимая «Отправить» вы даете Согласие на обработку персональных данных
Как настроить сбор данных без лишней нагрузки на инфраструктуру? Рассказала команда GMonit
13 марта мы провели технический вебинар «Сэмплирование в GMonit: как выбрать нужные данные и не потерять важное», в ходе которого обсудили, как настроить инструмент для сбора критически важных метрик, и рассказали, какие функциональные возможности GMonit помогают снизить затраты на мониторинг.
Технический директор GMonit Антон Новоженин объяснил, что такое распределенный трейс, как устроены спаны и почему сбор 100% данных — не всегда хорошая идея.
Технический директор GMonit Антон Новоженин объяснил, что такое распределенный трейс, как устроены спаны и почему сбор 100% данных — не всегда хорошая идея.

В мониторинге принцип тот же. Вместо хранения каждой метрики, трейса или события мы выбираем только те, которые дают общую картину или освещают критичные моменты. Этот подход помогает существенно сократить объемы хранимых данных, а значит, и нагрузку на инфраструктуру.
Участники рассмотрели три ситуации, когда оптимизация объема данных может навредить:
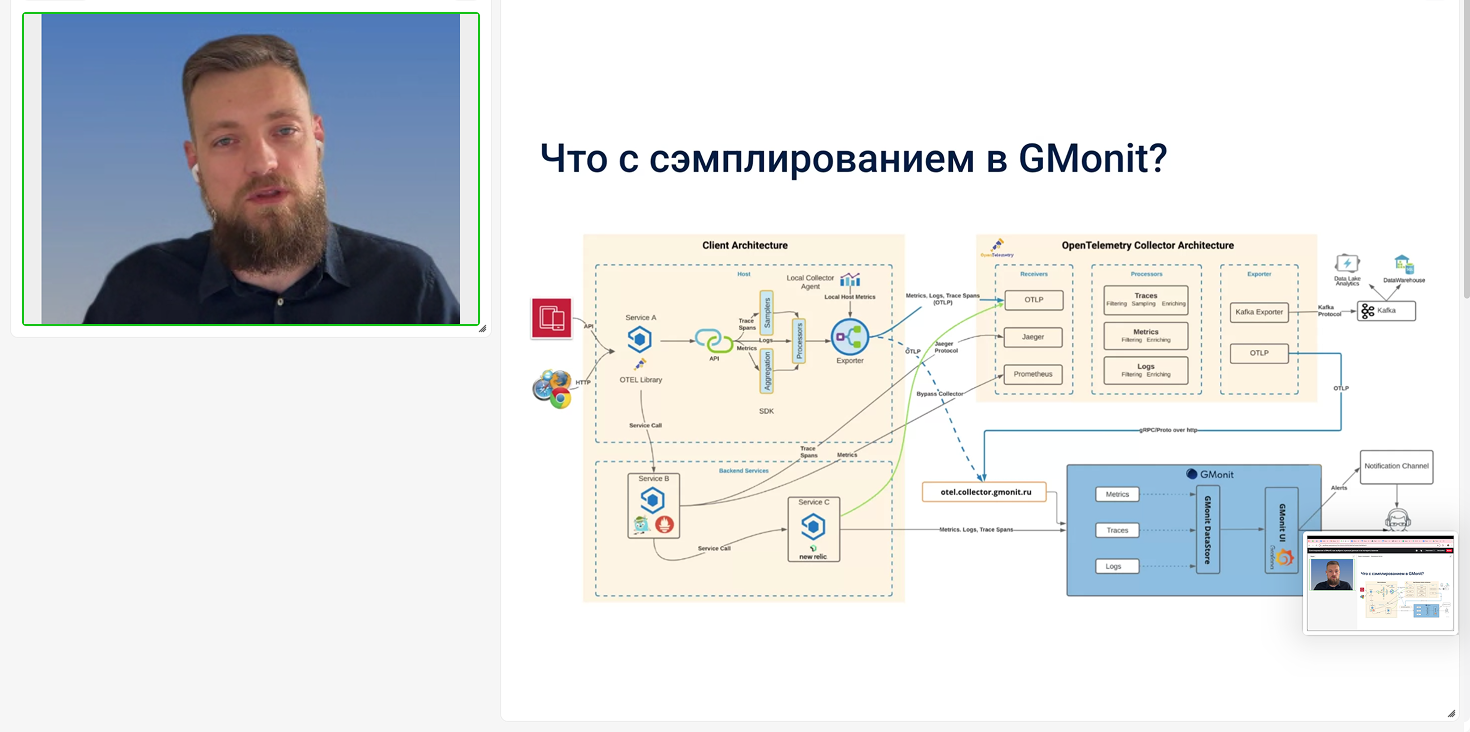
Также спикер рассказал, какие протоколы телеметрии поддерживает GMonit и пояснил, как сэмплирование реализовано в observability платформе.
- Необходимость полной детализации или жесткие нормативные требования.
- Малый объем трафика.
- Этап разработки или тестирования.
Также спикер рассказал, какие протоколы телеметрии поддерживает GMonit и пояснил, как сэмплирование реализовано в observability платформе.
В финальной части вебинара состоялась QA-сессия, где участники получили ответы на свои вопросы:
- Какой тип семплирования наиболее близок принципу 20/80.
- Как использовать GMonit, если внутри приложения работают агенты New Relic.
- Насколько увеличиваются затраты на вычислительные мощности при выборе tail-based сэмплирования.
- Как собрать все спаны с ошибками, не используя tail-based сэмплирование, и др.
Бонусом — спикер предложил участникам попробовать Lite-версию GMonit на облачной платформе Yandex. Этот инструмент хранит данные в течение трех дней и предоставляет весь необходимый функционал для анализа ключевых показателей производительности и решения базовых задач APM-мониторинга.
Предлагаем к просмотру видеозапись выступления